Description
(if you are not familiar with Zipf’s law, you may wish to look at the screenshots first, as they provide a visual context for the following)
Zipfstats is built around Zipf’s law, which states that given some corpus (in this case, a post/page) of natural language, the frequency of any word is inversely proportional to its rank in the frequency table. In a perfect Zipfian distribution, this would mean that the most frequent word in the corpus will occur twice as often as the second most frequent word, three times as often as the third most frequent word and so on. Any given real world corpus, if large enough, will tend to approximate a Zipfian distribution (this also works for cities as ranked by population, though that observation is less useful in this context).
The Zipfstats widget analyzes and reports word frequency by rank of a given single post or page (aka the corpus). The widget shows a small graph that plots the actual frequency-rank distribution of the content against a perfect Zipfian distribution, thus illustrating the degree to which the content follows Zipf’s law. It also provides for a table of the top-ranked words.
Zipfstats only analyzes the core content of a given post/page. It does not incorporate comments into its calculations. By default, it removes shortcode-generated content from its analysis, though you may optionally enable it. Filters, other than do_shortcode() (in the aforementioned case), are not affected in terms of the analysis. Actual output of the original content is unchanged, regardless of the options selected.
Options
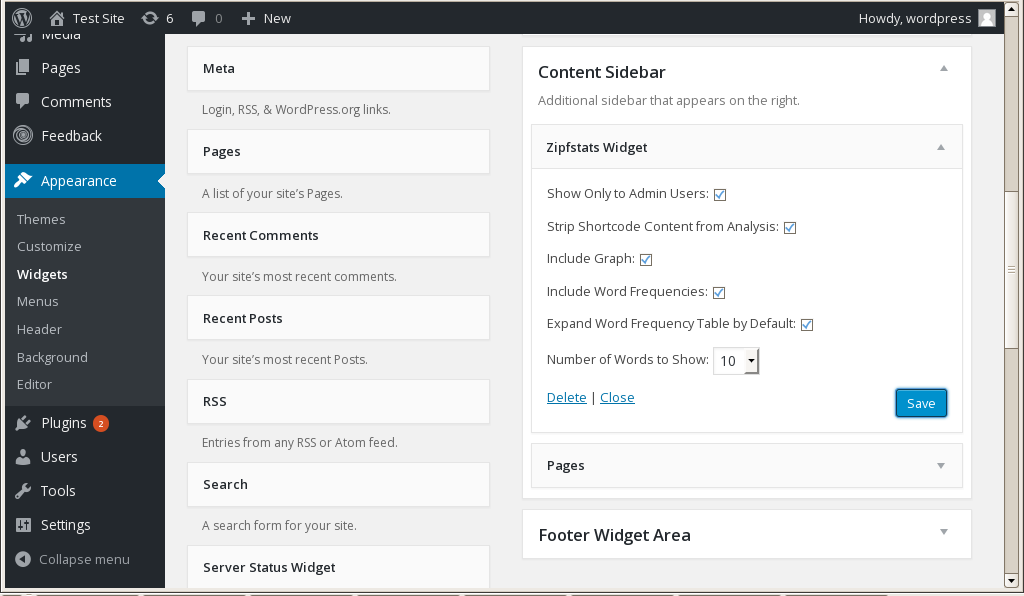
- Show Only to Admin Users (default = on): only admin-level users see Zipfstats output. If unchecked, all users, logged or non-logged, will see it.
- Strip Shortcode Content from Analysis (default = on): skips processing of and removes all shortcodes from the content of the post or page prior to analysis. Actual content remains unaffected.
- Include Graph (default = on): Display a log-log plot of word frequency data against a perfect Zipf distribution
- Include Word Frequencies (default = on): in addition to the Zipf plot, this option includes a table of the top n words in rank order as well as the frequency of their occurrences in raw terms. A clickable header allows the user to toggle between showing/hiding the wordlist.
- Expand Word Frequency Table by Default (default = on): if expand is selected, the wordlist (if also selected) will be displayed on initial page load. Unchecked, the user will have to toggle its display manually via a clickable header.
- Number of Words to Show (default = 10, max 25): this determines the number of words to appear in the “top n” wordlist table, if the latter is enabled. This option does not affect any calculations.
Some things to note:
- No site data is modified or stored. Widget results are generated on the fly. Zipfstats does not directly initiate any database activity, but merely uses the the $post object to analyze content, and the WordPress widgets API to store a handful of options.
- Post/page content will be displayed as normal. If the widget is added to a sidebar, it will appear where placed, again, without any change to existing post/page content.
Future Enhancements
- Add site-wide/category-wide/author-wide analyses
- Add to admin post/page edit
- Add recommendations to better approximate a Zipfian distribution
Screenshots




Installation
- Upload
zipfstats.zipto the/wp-content/plugins/directory and extract the contents of the zipfile - Activate the plugin through the ‘Plugins’ menu in WordPress
- Add the Zipfstats widget to a content bar
FAQ
- Why would I ever use this?
-
To find out how Zipfian your posts/pages are, and perhaps demonstrate that their content shows signs that the author is capable of using a natural language. Granted, Zipf’s law is not generally regarded as prescriptive, meaning that it’s not necessarily what a fluent writer in a given language should achieve, but there are arguments to the contrary. Mostly, because the graphs and tables are fun to look at (again, see screenshots).
- Will it work with insert_theme_name_here?
-
In terms of calculations, Zipfstats only takes into account post/page content.
Aspects of the widget display can be affected depending on theme
configuration. Most Zipfstats work was performed against the Twenty Fourteen
theme, as a point of reference. - Will it work with insert_plugin_name_here?
-
See above re: themes. If Zipfstats is set to strip shortcodes, then any content that is generated by a plugin’s shortcode(s) will be ignored for purposes of analysis. Aside from that, plugin behavior (and, again, the content) will be unaffected.
- Why do the numbers in the graph differ from those in the wordlist table/don’t correspond to my manual word count?
-
It is traditional to plot the log of rank and frequency rather than the raw numbers when conducting a Zipf analysis. The table reflects the raw data (i.e. “the” may have appeared 237 times, but that figure is plotted as the log of 237). The key is that the degree of Zipfian fit is reflected in the graph (the more linear, the more Zipfian).
Reviews
There are no reviews for this plugin.
Contributors & Developers
“Zipfstats” is open source software. The following people have contributed to this plugin.
ContributorsTranslate “Zipfstats” into your language.
Interested in development?
Browse the code, check out the SVN repository, or subscribe to the development log by RSS.
Changelog
1.2
- Tested up to WP 4.2. Updated to use PHP5 constructor to avoid deprecation warnings with WP 4.3. Made graph display optional per user request (arno756).
1.1
- Tested up to WP 4.1.
1.0
- Initial release.
This software is dedicated to my father. While, alas, this isn’t exactly a book, it does have to do with words, which is one step towards a book, I’m told.